

type
status
date
slug
summary
tags
category
icon
password
介绍
高性能计算(High Performace Computing,缩写 HPC)指使用多个处理器或者某一机群中组织的几台计算机的计算系统和环境,可以 执行一般个人电脑无法处理的大量资料与高速运算,其基本组成与个 人电脑并不存在太大的差异,但是其规格和性能要强大许多,作为计 算机科学的一个分支,它的应用范围很广,包括科学研究、气象预报、 计算模拟、军事研究、生物制药、图像处理等等。
并行计算
任何高性能计算和超级计算都离不开使用并行技术,并行计算是 指在并行机上,将一个应用分解成多个子任务,然后分配给不同的处 理器,各个处理器之间相互协同,并行地执行子任务,从而达到加快 求解速度、增大问题求解规模、节省时间等目的。
要实现并行计算,必须具备三个条件:并行机、应用问题具有并 行度和并行编程。
例如使用并行计算去进行求和运算:
假设,记,,,,则有
根据 Flynn 提出的指令流和数据流的概念,可以把计算机分为SISD、SIMD、MISD、MIMD 等四大类;按照结构模型,又可以分为共享存储对称多处理机系统(SMP)、分布共享存储多处理机系统(DSM)、大规模并行计算机系统(MPP)、机群系统(Cluster)等。
MPI并行编程
MPI(Message Passing Interface)是一种标准和函数库规范,并不是并行语言,是一种消息传递编程模型,具有较高的通信性能和可 移植性能。MPI让每个进程独立存在,享有独立的CPU和内存资源, 通过可靠的消息传递实现进程间的信息交换。
MPI 程序将所有进程放在一个有序的集合中并且为每个进程都 赋予唯一的序号,在一个进程组中的进程可以相互通信,通常默认使 用缺省的通信器 MPI_COMM_WORLD。
MPI的常用函数如下:
除此之外,MPI 还提供了一系列的函数用于阻塞式通信、非阻塞 式通信以及持久通信,这里就不一一列举了。
为了方便并行计算,MPI 还提供了规约函数 MPI_reduce 用于将 各个进程运行的结果规约到最终的结果上,如下:
OpenMP编程
共享存储并行模型,即多个 CPU 共享统一的内存空间,各 CPU 执行相同或不同的指令,通过共享内存实现通信,其可扩展性较差, 容易产生内存竞争的问题从而影响效率,仅适合中小规模的计算处理。
OpenMP(Open Multi-Processing)适合于 SMP 共享内存多处理 系统和多核处理器体系结构,是基于线程的并行编程模型,OpenMP 程序开始于一个单独的主线程,然后主线程保持串行执行,直到遇到 并行域(Parallel Region)然后开始并行执行并行域。
在 C 语言中,OpenMP 的并行化是通过嵌入到源代码中的编译制 导语句来实现的,支持并行区域、工作共享、同步等,支持数据的共 享和私有化。
编译制导语句通常由制导标识符、制导名称和子句组成,在使用 OpenMP 的过程中要注意一些问题,例如,如果对同一个变量进行写 操作,可能会造成“修改失败”等问题,并且糟糕的算法会导致并行 效率的低下等问题。
定积分求解圆周率
根据定积分公式可以求解圆周率:
使用SPMD编程模式求解的MPI程序
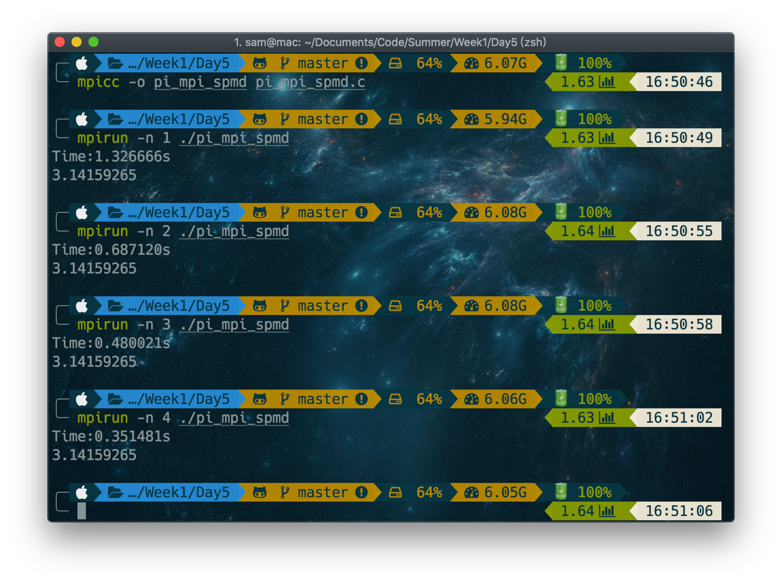
运行结果如下:
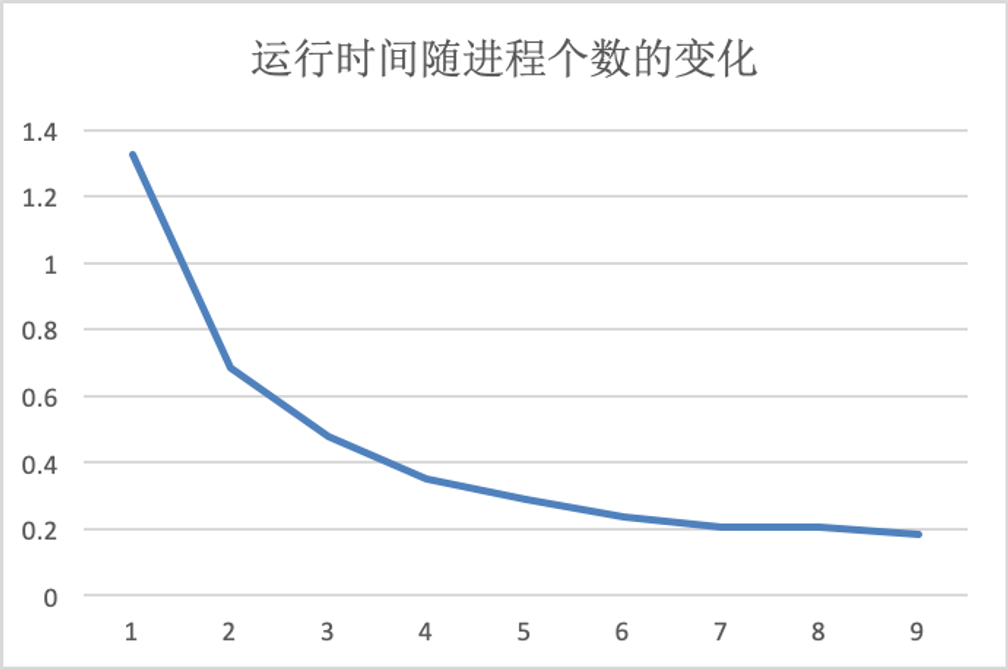
我测试了不同进程数对运算速度的影响,可以看到,随着进程数量的增加,刚开始程序的运行速度有显著的增加,但是与此同时,速度的提升越来越缓慢,进程数到达7以后,运行时间几乎不再有变化,因为此时不同进程间的通信也产生了大量的开销,因此很难进一步提升问题的求解速度。
OpenMP并行域求解
使用OpenMP进行并行域求解,即在并行域中,对每个线程负责的矩形块进行分组求和并用数组进行存储,数组的下标对应当前线程的序号,最后再回到串行域中,将所有线程的sum累加求和即可。
OpenMP for循环制导求解
对于for循环制导,表面上它只进行了一遍从1到n的for循环,然而它会自动将制导符下面的for循环拆分成多个块,并将每个块分配给各个线程并行执行。由于编译和执行过程和之前的方法一样,因此这里就不做截图。
OpenMP reduction子句for循环制导求解
使用reduction子句的for循环制导和之前的代码并没有太大变化,这里不再使用sum数组来存放每个线程的运算结果,而是直接在for循环制导中,将每个线程的运算结果使用reduction规约累加到变量sum上,最后再将sum乘上dx即为最终的运行结果。
OpenMP使用private子句和critical制导求解
在并行域中,如果我们直接令pi += sumdx,可能会导致多个线程同时对pi进行操作,例如,线程1和2同时取出pi = 0,然后线程1令pi += 0.2,然后写回,此时pi = 0.2;与此同时,线程2令pi += 0.3,然后写回,此时pi = 0.3;若线程2后执行完,那么线程1执行的结果就回被线程2执行的结果所覆盖掉,导致最后的pi = 0.3而不是等于正确结果0.5,因此我们要使用critical制导,critical(临界段)可以保护共享变量的更新,避免数据竞争,critical制导内的代码同一时间只能有一个线程执行。即线程1在对pi进行操作的时候线程2只能等待,这样可以保证并行计算执行结果的正确性。
MPI+OpenMP并行求解
在熟悉了解了MPI和OpenMP两种并行方式后就可以很容易地将这两种方式结合起来进行混合并行。首先通过MPI将求解的过程划分给不同的进程去执行,对于每个进程内部的for循环,使用OpenMP开启多个线程使用reduction规约求和,将每个进程内部的所有进程求和后,再使用MPI的reduce函数将每个进程的最终运算结果累加到变量pi上。
在实际操作过程中,使用MPI和OpenMP混合编程时,编译时的指令需要进行修改,在Linux上,可以直接使用如下指令进行编译:
mpicc -fopenmp -o pi_mpi_openmp pi_mpi_openmp.c注:在macOS上使用Homebrew安装的mpich默认使用clang进行编译,然而clang本身并不支持OpenMP,这里仅需修改mpicc配置文件中的CC参数,将其改成gcc-8即可,或者直接在命令行中加入cc参数,如下:
mpicc -fopenmp -o pi_mpi_openmp pi_mpi_openmp.c -cc=gcc-8- 作者:PLUS
- 链接:https://tangly1024.com/article/cugb-high-performance-computing
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。











